

GPU服务器中的ETH、RDMA、GID、NVLink分别是什么?
发布时间:2026-06-02 14:31:31 作者:超级管理员 点击:30 【 字体:大 中 小 】
英伟达的旗舰机型,GB300的核心优势不止在于Grace CPU+Blackwell Ultra GPU的超强硬件配置,更在于一套分层、高速、低延迟的互联传输体系。很多时候会被四个名词绕晕:ETH、GID、RDMA、NVLink。

它们到底各自是什么?谁负责内网、谁负责外网?谁依赖谁、谁限制谁?算力跑不满、集群通信卡顿、RDMA掉线,根源大多藏在这四者的联动逻辑里。
一、四大核心组件,到底各司什么职?
先摒弃晦涩的官方术语,用「算力传输分工」的通俗视角,逐个读懂四个核心概念,结合GB300硬件特性精准解读。
1. ETH(以太网网卡):服务器的「通用网络底座」
ETH就是我们最熟悉的
传统以太网接口/网卡,是所有服务器的基础网络硬件,也是GB300整个互联体系的物理载体之一。在GB300高性能服务器中,ETH不再是普通办公千兆网卡,而是搭载NVIDIA Spectrum-X高速智能以太网卡,支持万兆、25G、100G甚至更高带宽,是集群管理、数据交互、外网连通的基础硬件。核心作用:承担服务器常规管理、日志传输、远程运维、存储挂载等通用网络任务;是RoCE架构下RDMA高速传输的物理基础,简单说:GB300的RDMA功能,必须依托ETH高速网卡硬件才能实现;负责集群南北向、东西向的基础数据流转,是整个网络体系的“地基”。通俗总结:ETH是路,是所有网络传输的物理通道,普通网络走普通路,高速RDMA走优化后的高速ETH路。
2. RDMA(远程直接内存访问):集群高速通信的「加速黑科技」
传统以太网传输数据,需要经过CPU拷贝、系统内核调度、协议解析,多一次转发就多一份延迟、多一份算力损耗。而RDMA(远程直接内存访问),就是为高性能算力集群量身打造的传输协议,核心是绕开CPU、绕过内核,直接实现服务器间内存数据读写。在GB300集群中,主流采用RoCE(以太网RDMA)架构,让高速以太网网卡具备RDMA能力,兼顾通用性与高性能。核心优势:零CPU占用、极低延迟、超高吞吐,完美适配GB300大规模AI模型训练、超算并行计算的海量数据交互需求。通俗总结:ETH是马路,RDMA就是这条马路上的「高速直达专用车道」,不堵车、不绕路、无需人工调度,极速传输数据。
3. GID(全局唯一标识符):RDMA通信的「专属门牌号」
很多人搞不懂GID,其实它是
RDMA通信的核心寻址标识,全称Global Identifier(全局标识符)。在GB300的RoCE网络体系中,每一个支持RDMA的ETH网卡端口,都会自动生成专属GID,相当于RDMA通信的唯一“身份ID+门牌号”。核心特性:GID依托ETH网卡的IP地址自动生成,分为IPv4映射型和IPv6原生型,适配不同RoCE协议版本;一台服务器多张RDMA网卡、多个端口,会对应多个不同GID,精准区分通信端口;集群内所有节点的RDMA通信,都依靠GID寻址配对,没有合法GID,RDMA高速通道直接失效。单网卡为何会分配4个GID?一对多映射的核心原理:在GB300的RoCE网络环境中,经常出现「一个ETH RDMA网卡端口,自动生成4个不同GID」的现象,这是正常机制而非故障,核心由RoCE协议版本+IP协议栈+通信适配模式共同决定。具体拆分:RoCE分为RoCEv1和RoCEv2两个主流版本,同时网卡默认兼容IPv4、IPv6双协议栈,两种协议版本×两种IP协议栈,正好组合出4组通信适配规则,系统会为每组规则独立生成一个专属GID,最终形成单网卡4个GID的「一对多」映射关系。4个GID的分工与作用:4个GID并非冗余重复,而是各司其职适配不同集群通信场景。其中IPv4映射GID适配传统IPv4集群环境、兼容RoCEv1老旧协议;IPv6原生GID适配新一代高速IPv6集群、支持RoCEv2低延迟协议。多GID机制让单张RDMA网卡可以同时对接不同协议、不同网段的集群节点,实现「一个网口,多协议兼容、多场景适配」,极大提升GB300集群组网的灵活性和兼容性。一对多映射的核心意义:普通网络是「一个端口对应一个标识」,而RDMA的GID一对多机制,是为了突破单一协议限制,让单网卡端口具备多链路、多协议并行通信能力。在大规模AI集群中,可同时兼顾新旧集群架构、双栈网络互通,避免协议不兼容导致的RDMA断连、通信受限问题,也是GB300适配超大规模异构集群的核心设计。通俗总结:ETH是路,RDMA是高速车道,GID就是车道上的「唯一门牌号」,没有门牌号,数据就找不到收发节点,无法完成高速通信。
4. NVLink:单柜多卡的「算力超级桥梁」
如果说ETH/RDMA/GID是
多柜服务器之间的集群互联体系,那NVLink就是单柜GB300服务器内部,GPU与GPU、GPU与CPU的专属高速互联总线。GB300搭载第五代NVLink 5.0技术,是NVIDIA专属的硬件级高速互联协议,也是GB300 NVL72架构的核心支撑。单台GB300可实现72块Blackwell Ultra GPU全网状互联,整机NVLink交叉带宽高达130TB/s,单GPU带宽可达1.8TB/s,转发延迟低至300ns级别。核心作用:实现单柜内多GPU显存、算力资源池化,让多卡协同工作如同单卡,彻底消除多卡通信瓶颈;支撑超大AI模型分布式推理、并行训练,解决单机算力拆分、数据同步延迟问题;仅用于服务器内部硬件互联,不跨服务器、不用于外网集群通信。通俗总结:NVLink是「单柜内部的超级高速通道」,负责一柜机器里所有GPU的算力互通;ETH/RDMA/GID是「机器和机器之间的互通通道」,负责集群整体算力联动。
二、核心层级:四者的底层架构关系,一眼看懂
理清定义后,最关键的就是
层级分工,这是解决90%GB300网络、算力问题的核心:
1. 内网(单柜)层:NVLink独占算力互通
单柜GB300服务器内部,所有GPU、Grace CPU的高速数据交互,
完全由NVLink接管,不经过ETH、不占用RDMA资源。NVLink的优先级、带宽、延迟,远高于所有以太网体系传输,是单柜算力释放的核心保障。
2. 外网(集群)层:ETH+RDMA+GID三位一体
多台GB300服务器组成超算集群后,服务器与服务器之间的高速数据同步、任务调度、算力协同,依靠这套体系运行:ETH:物理硬件载体,提供高速传输通道;RDMA:传输协议核心,实现无损耗、低延迟高速通信;GID:寻址核心,保障集群内节点精准配对通信。终极层级总结:NVLink管单柜算力,ETH-RDMA-GID管集群算力,两套体系相互独立、互补协同,共同撑起GB300的极致算力性能。
三、运维避坑:四大常见故障与核心优化思路
结合四者的关联逻辑,整理GB300集群最常见的问题与优化方向,实战直接能用:问题1:网卡能上网,但RDMA不通:大概率是GID配置异常、端口绑定错误,优先检查GID列表有效性,排查IP变更后的GID刷新状态;问题2:集群训练速度慢、延迟高:优先排查ETH硬件带宽、网线规格,确认RDMA协议开启,同时检查NVLink拓扑是否完整,排除单机多卡瓶颈;问题3:多机负载不均、部分节点闲置:多为GID与RDMA端口映射错乱,导致部分节点通信优先级异常,重新校准GID与网卡端口绑定关系即可;优化核心:NVLink保证单机无瓶颈,ETH保证物理链路稳定,GID保证寻址精准,RDMA保证传输高效,四者缺一不可。
四、GB300的算力底层逻辑
最后用一句话彻底总结四者的关系,方便大家记忆:NVLink是GB300的「单柜算力血管」,ETH是集群通信的「物理骨架」,RDMA是高速传输的「血液流速」,GID是精准通信的「定位坐标」。四者分工明确、层层嵌套、互补协同:NVLink搞定单柜多卡极致性能,ETH+RDMA+GID搭建稳定高效的集群高速互联体系,共同构筑了GB300顶级AI算力服务器的核心竞争力。












单季暴增83.7%,NAND五大厂营收破389亿美元,SSD缺货涨价厂商赚麻了!

国产卡是如何兼容CUDA的?

AutoDL 算力平台|弹性普惠算力,让 AI 开发零门槛

上新!移动模型服务平台MoMA上架多款千问旗舰模型
约20亿投资·140MW供电·万P算力·PUE低于1.23尚航无锡(惠山云)国际智算中心深度分析

总投资24亿!中国银联黄山数据中心园区项目正式通电

西柚云超算与云南联通正式达成战略合作,将共建云南科研超算中心节点

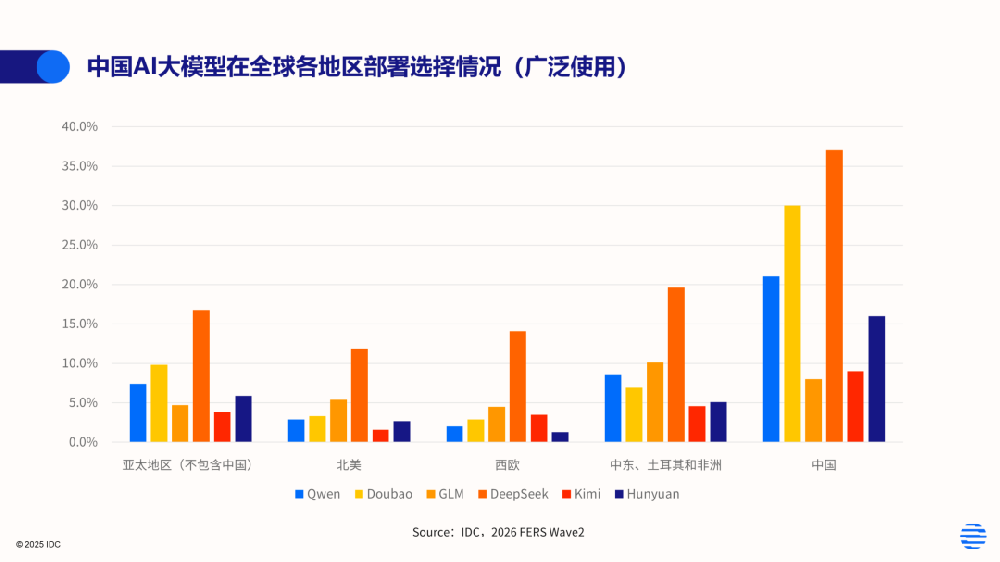
全球竞争格局下的中国AI模型:激流勇进,但信任尚待跨越
重磅发布!AI 芯片安可测评结果:华为海思、阿里平头哥、海光、沐曦、摩尔线程、壁仞、天数智芯

不用花一分钱!Claude Code接入DeepSeekV4完整教程

算力成本失控:CPU两轮涨价超40%,内存半年翻倍,高端GPU租赁排到2027年

2026 大模型 GPU 选型全指南|从消费游戏卡到超算卡,适配全系列 DeepSeek 模型部署
极智算算力平台|硬核算力底座,赋能 AI 全域高效落地
GTX显卡和RTX显卡的区别是什么?
2026年大模型全景:国内外总览
10大算力芯片全解析:CPU/GPU/TPU/NPU/LPU/FPGA......
DeepSeek-V4.1 定档 6 月之核心技术深度前瞻!2026
北京 A100-40G 现货出租
GPU服务器中的ETH、RDMA、GID、NVLink分别是什么?
总投资约50亿!交通银行贵安数据中心正式接入电网
